In the world of voice acting, there is a legend named Mel Blanc, "The Man of a Thousand Voices." He wasn't just Bugs Bunny; he was also Daffy Duck, Porky Pig, and Barney Rubble. The genius of Blanc wasn't just that he could create different voices, but that he could make any one of those voices express a universe of emotion - Bugs could be triumphant, terrified, or tricky, yet he always sounded like Bugs. This is the hallmark of a great performance: consistency of character, with infinite emotional variety.

When you first clone your voice with AI, it's a magical moment. You hear your own vocal identity - your unique timber and cadence - replicated perfectly. But for many, a second feeling quickly follows: disappointment. The clone is perfect, but it's perfectly flat. It's a snapshot of you speaking in a neutral, monotonous tone. It's the vocal equivalent of a passport photo. It’s you, but without any life.
This is the "Monotone Valley," and it’s where the true potential of voice cloning is often lost. The goal isn’t just to replicate your voice; it's to direct it. It's to become the Mel Blanc of your own brand, capable of making your single, authentic voice sound energetic for a marketing video, calm for a meditation app, or serious for a corporate training module.

This report will move beyond basic replication to provide a playbook for becoming a "vocal director" for your AI digital twin. We will explore the art and science of using preset emotional styles and manual controls to craft dynamic, expressive performances, ensuring your cloned voice is not just a copy, but a versatile and powerful instrument for any content need.
The Authenticity Trap: Why "Perfect" Isn't Always "Good"
The initial goal of voice cloning was perfect replication. The industry poured billions into creating AI voices that were indistinguishable from the source. But in achieving this, they hit a psychological barrier. A voice that is perfectly consistent but emotionally flat is, in many contexts, perceived as less authentic than a human voice that has natural variations.
Content requires context. A single, neutral tone fails across the board:
eLearning: A flat voice can be disengaging and has been shown to reduce knowledge retention.
Marketing: An unenthusiastic voiceover for an exciting product feels disconnected and untrustworthy.
Audiobooks: A story narrated without any emotional inflection for the characters falls completely flat.
FROM THE TRENCHES
"The biggest challenge in synthetic voice is prosody - the rhythm, stress, and intonation of speech. It’s easy to get the words right, but it's the music behind the words that conveys emotion. We spent years in post-production manually adjusting pitch and timing to add life to computer-generated voices. The idea that a user can now do this with a simple dropdown menu is revolutionary."
— Rebecca Goldman, veteran audio post-production engineer for film and television.
The solution isn’t to abandon the consistency of a cloned voice, but to layer emotional intent on top of it.
The Director's Toolkit: The Two Pillars of Vocal Expression
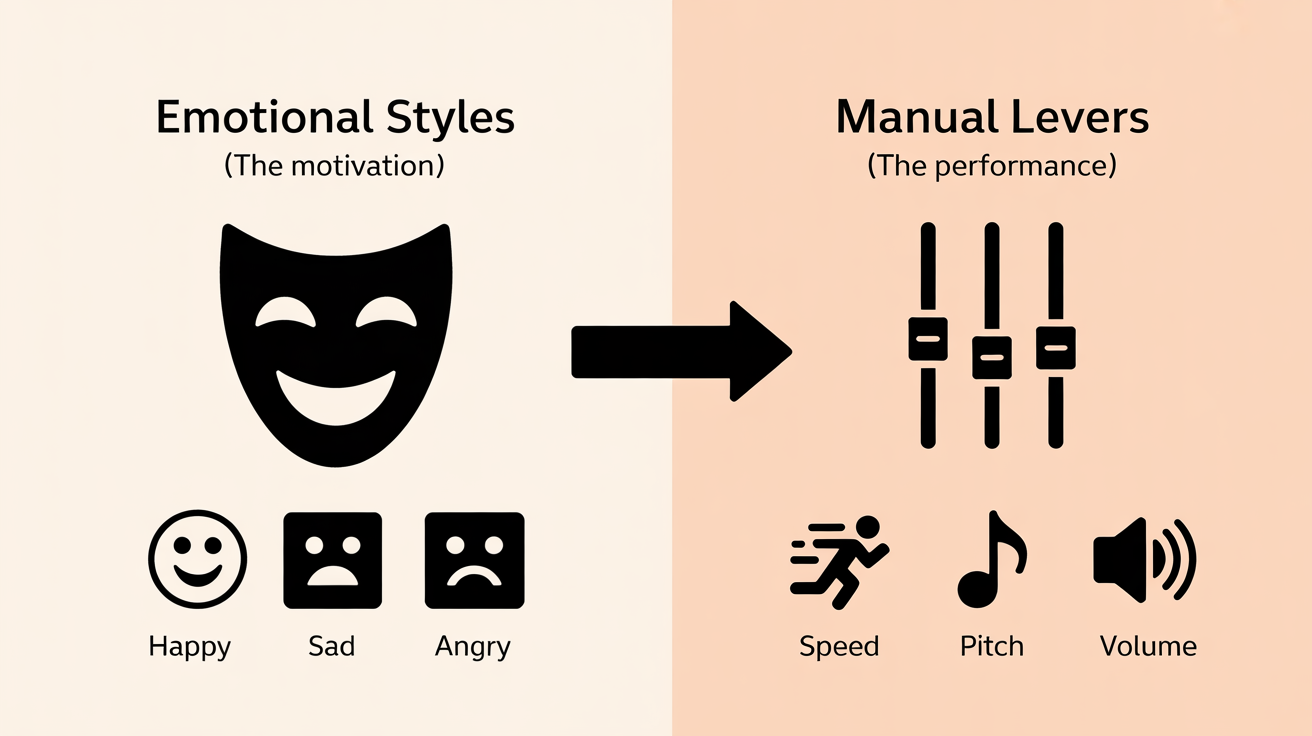
To direct your voice clone, you have two primary sets of tools. Mastering the interplay between them is the key to creating a truly expressive performance.
1. The Preset Emotional Styles (The "What")
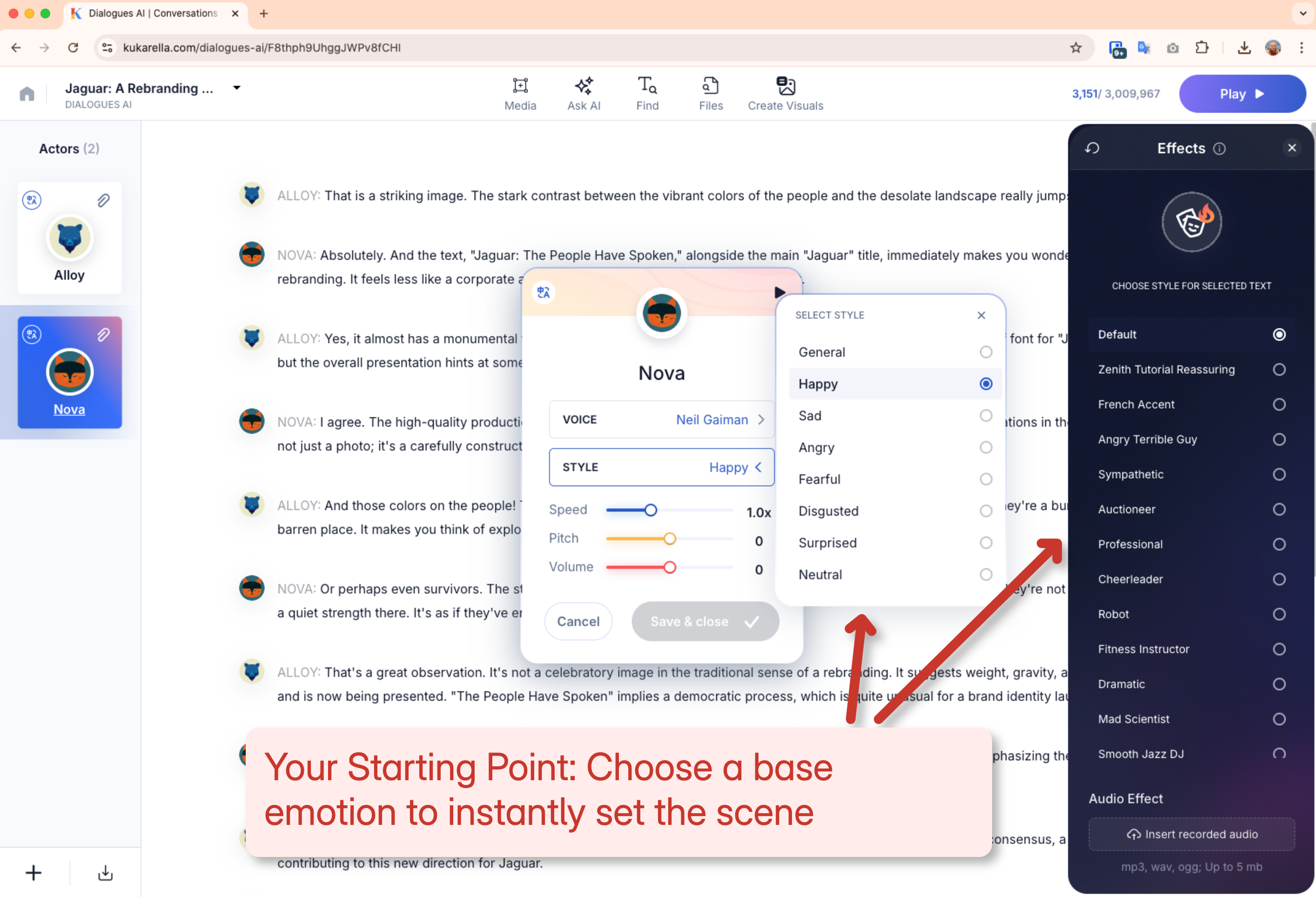
This is the foundational layer. On a platform like Kukarella, when you use a cloned voice, you are presented with a list of pre-defined emotional styles. These are professionally trained models designed to alter the core performance of your voice to match a specific mood. These typically include:
- Happy/Excited: Adds an upbeat lilt and slightly faster pace.
- Sad: Introduces a slower pace and often a lower, more somber tone.
- Angry: Adds a harder edge and more intensity to the delivery.
- Fearful: Often results in a slightly higher pitch and a more hesitant cadence.
- Narrative: A balanced, clear style ideal for storytelling and neutral narration.
- Neutral: The baseline, uncolored performance.
Think of these styles as your actor's "base motivation" for a scene.
2. The Manual Effects Levers (The "Fine-Tuning")
If styles are the motivation, the manual levers are the specific physical performance. These are the sliders for Speed, Pitch, and Volume.
- Speed: Controls the pace of the delivery. A slight increase (1.05x) can add energy, while a slight decrease (0.95x) can add weight and seriousness.
- Pitch: Alters the baseline pitch of your voice. A small positive adjustment can convey excitement or youth, while a negative adjustment can add gravity or authority.
- Volume: Controls the perceived loudness or presence of the voice.
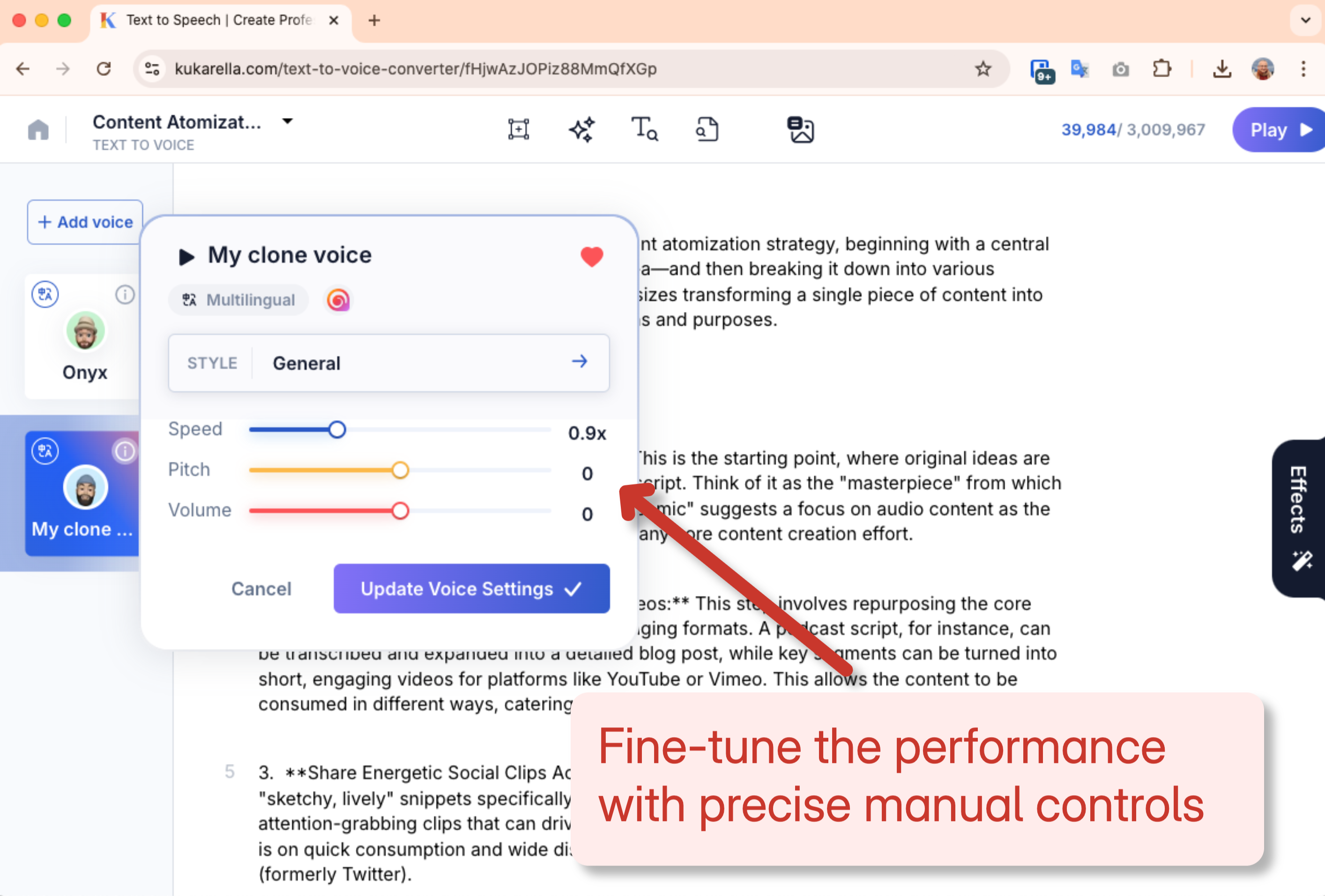
The true art is not in using one or the other, but in combining them to create a unique "vocal recipe" for your specific needs.
The Tool Ecosystem for Emotional Control
| Tool | Emotional Control Method | Key Differentiator | Best For |
| Kukarella | Pre-set Styles + Manual Sliders. | Paragraph-Level Control. The ability to apply different styles to different paragraphs within one script is a unique storytelling advantage. | Creators who need dynamic, multi-emotional performances for narratives, audio dramas, or varied content. |
| ElevenLabs | "Style" & "Clarity" Sliders. | Generative Expressiveness. The "Style" slider can generate highly expressive, sometimes unpredictable performances from high-quality clones. | Audio purists who want the most realistic and nuanced single-emotion performance and are willing to experiment to achieve it. |
| Descript | Limited ( baked into clone). | Text-Based Correction. Emotion is primarily captured in the source recording for the "Overdub" feature, with limited post-production control. | Users whose primary need is to correct words in an existing human recording, rather than directing an AI performance. |
| Play.ht | SSML Tags & Manual Sliders. | Developer Control. Offers deep, granular control via SSML (Speech Synthesis Markup Language) tags for those with technical skill. | Developers and power-users who are comfortable writing code-like tags directly into their script for precise vocal control. |
The Alchemist's Playbook: Four Recipes for Expressive Voice
Here are four practical, documented recipes for combining styles and effects to achieve specific, high-value outcomes.
1. Recipe for: The Engaging Educator
Goal: To create a voice for an online course that is clear, authoritative, but also warm and engaging to keep students focused.

The Recipe:
- Style: Narrative (Provides a clear, storytelling base)
- Speed: 1.05x (A slightly faster pace keeps the energy up and prevents the lecture from dragging)
- Pitch: +0.5 (A very subtle pitch increase adds a touch of friendliness and enthusiasm)
- Volume: 0 (Standard volume is fine for clarity)
Result: A voice that sounds knowledgeable and trustworthy, but also approachable and interesting to listen to for an extended period.
2. Recipe for: The High-Energy Marketer
Goal: To create a voiceover for a YouTube ad or a social media promo that grabs attention and conveys excitement.

The Recipe:
- Style: Happy (Sets the foundational tone to be upbeat)
- Speed: 1.1x (The increased pace creates a sense of urgency and excitement)
- Pitch: +1.0 (A noticeable but not cartoonish pitch increase reinforces the positive energy)
- Volume: +1 (Makes the voice "pop" in the audio mix)
Result: A dynamic, attention-grabbing vocal performance that is perfect for short, high-impact promotional content.
3. Recipe for: The Trustworthy Corporate Narrator
Goal: To create a voice for a serious corporate training module or a C-suite presentation that conveys authority, calm, and confidence.
The Recipe:
Style: Neutral (Avoids any unwanted emotional coloring)
- Speed: 0.95x (Slowing down slightly makes the speaker sound more deliberate and thoughtful)
- Pitch: -0.5 (A subtle drop in pitch adds a sense of gravity and authority)
- Volume: +0.5 (A slight boost ensures the voice is clear and present)
Result: A voice that sounds professional, credible, and serious, building trust with the listener.
4. Recipe for: Creating Emotions Not on the List (e.g., Sarcasm)
Goal: The style menu doesn't have a "Sarcastic" button. You have to create it. Sarcasm is often conveyed by saying positive words in a negative or detached tone.
The Recipe:
- Style: Angry or Sad (This is the secret. Use an opposite emotional style to create tonal dissonance with the positive words in your script.)
- Speed: 0.9x (A slower, drawn-out delivery is often key to sarcasm)
- Pitch: Variable (This might require generating line-by-line, slightly raising the pitch at the end of a word for that classic sarcastic inflection).
Result: By combining a "negative" style with "positive" text and a slower pace, you can create a convincing sarcastic performance, proving you can create vocal textures far beyond the default menu.
"Plot Twist" Moment: One Voice, Many Emotions = Deeper Connection
The common assumption is that to get variety, you need a variety of voices. But psychological studies on parasocial relationships (the one-sided bond audiences form with media figures) suggest the opposite is true.
The Twist: A stronger audience connection is formed when the same, single voice demonstrates a range of emotions. When your audience hears your authentic voice clone express excitement in one video and seriousness in another, it doesn't register as inconsistency. It registers as personality. It makes the AI voice feel less like a tool and more like a person with emotional depth. Using one consistent voice across all your content, but tailoring its emotion to the context, is far more powerful for brand-building than using ten different, disconnected AI voices.
Troubleshooting & Problem-Solving
Q: "I selected the 'Happy' style, but my clone still sounds flat. Why?"
A: The emotional styles are powerful filters, but they work with your source audio. If your original cloned voice is extremely monotone, the "Happy" style can only do so much. The solution is to amplify the effect using the manual levers. Boost the pitch and speed slightly along with the "Happy" style to get the energetic result you want.
Q: "The 'Angry' style just sounds like it's shouting. How do I get a more subtle, 'seething' anger?"
A: This is a perfect use case for the "recipe" approach. Shouting is easy. Subtle emotion is hard. Try this recipe: Style: "Angry" + Speed: 0.9x + Pitch: -1 + Volume: -1. This combination creates a voice that is low, slow, and quiet, but with the intense undertone of the "Angry" style, resulting in a much more menacing and subtle performance.
Q: "How do I keep all my character voices straight for my audiobook?"
A: Do not rely on memory. Create a "Vocal Style Sheet," just like a character sheet. For every character, write down the exact recipe you use (e.g., "Grok the Orc: Style=Angry, Speed=0.9, Pitch=-2"). When that character speaks, you simply dial in their settings. This ensures perfect consistency across hundreds of pages.
"The Fine Print": The Ethics of Emotional Manipulation
Misleading Context: The ability to make a voice clone sound angry or sad comes with the responsibility not to misrepresent. It would be highly unethical to take a neutral statement someone made, clone their voice, and apply the "Angry" style to make it sound like they were threatening someone.
The Limit of AI Emotion: It is critical to remember that the AI does not understand emotion. It is applying a mathematical transformation to audio waves. It doesn't know why a line is sad. Therefore, it can sometimes apply the style inappropriately within a sentence. The human director's job is to listen and ensure the performance makes sense in context, sometimes needing to generate a line with a neutral style if the emotional filter gets it wrong.
Frequently Asked Questions (FAQ)
Q: Do I have to set the style for every single paragraph?
A: No. You can set a default style for your voice clone that will apply to all text. You only need to manually override it for specific paragraphs or lines where you want a different emotional performance.
Q: Do these emotional styles work for all languages on a multilingual clone?
A: Yes. A key feature of advanced platforms like Kukarella is that the emotional styles carry over when you switch languages. Your clone can sound "Happy" in English, and when you translate the text to French, it will apply the same "Happy" prosody to the French audio.
Q: Can I create my own custom, prompt-based styles like "Tender Storyteller" for my cloned voice?
A: This is a crucial distinction. As of now, the advanced, prompt-based "Custom Voice Styles" are typically available for specific, high-end TTS voices (often from providers like OpenAI). Cloned voices use the powerful combination of pre-set emotional styles (Happy, Sad, etc.) and the manual effects sliders (Speed, Pitch, Volume) to achieve their emotional range.
Your voice clone is not a static photograph. It is a dynamic, living instrument. And with these tools and techniques, you are its sole director.