1. The Hook: The Voice in the Machine
 Your voice is data now
Your voice is data nowIn late 2021, the family of Val Kilmer, the iconic actor who lost his voice to throat cancer, announced something unprecedented. They had partnered with a tech company to create a perfect digital replica of his original voice. Using hours of archival audio from his films, an AI model was trained to speak in Kilmer’s classic, recognizable tones. He could now use this "clone" to communicate, narrate projects, and preserve his vocal legacy. As Kilmer himself put it, it was a way to "perfectly restore my voice."
This wasn't just a sci-fi gimmick; it was a watershed moment. Voice cloning—once the domain of high-end research labs and visual effects studios—had become accessible, powerful, and deeply personal. It's a technology that allows podcasters to fix audio mistakes without re-recording, empowers brands to create perfectly consistent voiceovers, and gives a voice back to those who have lost it.
But how does it actually work? What are the hidden risks? And how can you create your own professional voice clone, step-by-step? This guide will unveil the complete story, from the robotic origins of speech synthesis to the hyper-realistic models of today, providing everything you need to know to safely and effectively clone your own voice.
2. The Complete Picture: From HAL 9000 to Hyper-Realism
The journey to realistic voice cloning is a story of moving from "pasting sound" to "generating speech." The technology has evolved through several distinct eras.
 evolution of speech synthesis from 1961 to present
evolution of speech synthesis from 1961 to present- Title: The Evolution of Speech Synthesis
- 1961: The First Song: An IBM 7094 computer sings "Daisy Bell," the first instance of computer-synthesized speech, inspiring a key scene in 2001: A Space Odyssey.
- 1980s-1990s: Concatenative Synthesis: The era of Stephen Hawking's voice. This method involved recording a person saying thousands of tiny sound units (diphones) and then stitching them together to form new words. The result was intelligible but distinctly robotic.
- Early 2010s: Parametric Synthesis: This approach used statistical models to generate speech from acoustic features like pitch and speed. It was more flexible than concatenation but often sounded muffled or "buzzy."
- 2016: Google's WaveNet: The breakthrough moment. DeepMind introduces a deep neural network that models the raw audio waveforms of human speech. This was the birth of modern, natural-sounding Text-to-Speech (TTS).
- 2020-Present: Generative Cloning & Style Transfer: The current state-of-the-art. Instead of just reading text, models can now learn the unique characteristics of a specific voice from just a few seconds of audio and apply that "style" to any text, even adding emotion. This is the technology that powers today's leading voice cloning platforms.
The market has exploded accordingly. The global voice cloning market was valued at approximately $1.5 billion in 2023 and is projected to grow to over $12 billion by 2030, according to a report by Grand View Research. This growth is driven by its adoption in everything from entertainment and marketing to healthcare and education.
3. Deep Dive: The Science of "Stealing" a Voice
Voice cloning isn't magic; it's a combination of sophisticated AI models. There are two primary approaches used by today's leading platforms.
Approach 1: Zero-Shot (or Few-Shot) Voice Cloning
This is the most common and accessible method, pioneered by platforms like ElevenLabs.
- How It Works: The AI model is pre-trained on a massive dataset of thousands of different voices and languages. This gives it a deep, generalized understanding of human speech. When you provide a short audio sample (the "shot"), the model doesn't learn to speak from scratch. Instead, it analyzes the unique acoustic properties of your voice—your pitch, cadence, and timbre—and identifies these as a "voice style." It then uses its existing knowledge to render new text in that specific style.
- Analogy: It's like a master impressionist who can listen to someone speak for 30 seconds and then deliver a convincing imitation. The impressionist already knows how to speak; they are just applying a new vocal "filter."
- Pros: Incredibly fast, requires very little sample data (often under a minute), and is great for rapid content creation.
- Cons: Can sometimes struggle to capture the full nuance of a voice and may have minor artifacts (we bet you saw that).
From the Trenches: A user on r/voiceai (May 2024) commented on this method: "The speed of ElevenLabs is insane. I uploaded a 1-minute clip of my podcast intro, and five minutes later, I was generating new lines to fix mistakes. It's not 100% perfect, but it's 98% there, and that's a lifesaver."
Approach 2: Professional Voice Cloning / High-Fidelity Training
This is the method used for creating ultra-realistic, professional-grade clones, often offered by platforms like Resemble AI and Descript.
- How It Works: This approach involves training a dedicated neural network specifically on your voice. Instead of just a few seconds of audio, you need to provide a much larger dataset—often 30 minutes to several hours of clean, high-quality recordings. The AI uses this extensive data to build a detailed, bespoke model of your unique vocal characteristics.
- Analogy: This isn't an impressionist doing an imitation; this is a dedicated student learning to speak exactly like their teacher, mastering every subtle inflection over weeks of practice.
- Pros: Creates the most realistic and controllable voice clones, capturing subtle nuances that zero-shot models might miss.
- Cons: Requires significant time and effort to provide the training data, and is typically much more expensive.
Reality Check: The "Garbage In, Garbage Out" PrincipleMyth: You can create a perfect voice clone from a noisy phone call recording.
Reality: The quality of your input audio is the single most important factor in the quality of your clone. For professional cloning, this means recording in a quiet room with a high-quality microphone. Even for zero-shot cloning, a clean sample is crucial.
4. The Tool Ecosystem: A Comparative Analysis
Choosing the right tool depends entirely on your needs: speed, quality, or features.
| Tool | Cloning Method | Required Audio | Key Differentiator | Best For... | Pricing Model |
| Kukarella | Few-Shot Cloning | 15 seconds | Emotional Styles. The ability to apply styles like "Cheerful," "Sad," or "Angry" to your cloned voice. | Content creators needing both a custom voice and emotional range for dynamic narration. | Subscription (Included in paid plans) |
| ElevenLabs | Zero-Shot & Professional | 1 min (Instant) / 30+ mins (Pro) | Speed & Realism. Highly realistic voices from minimal data, but known for emphasis errors. | Podcasters, audiobook narrators, and developers needing top-tier realism, fast. | Freemium / Subscription / Pay-as-you-go |
| Descript | High-Fidelity Training | 10-30 minutes | Overdub Feature. Seamlessly integrated into their audio/video editor for correcting words. | YouTubers and editors who primarily need to fix mistakes in existing recordings. | Subscription (Part of Descript Pro) |
| Resemble AI | High-Fidelity & Real-Time API | 30+ minutes | Real-Time API. Geared towards developers building applications with conversational AI agents. | Businesses building custom voice applications like call center bots or in-game characters. | Enterprise / Pay-as-you-go |
Where Kukarella Fits: The Expressive Storyteller
While some platforms chase perfect human mimicry, Kukarella has focused on a different, equally important challenge: emotional intelligence. Its key innovation isn't just cloning a voice; it's the ability to direct that cloned voice. After creating your voice clone from a 15-second sample, you can apply dozens of pre-set emotional and professional styles to it. This means you can use your own voice to narrate a cheerful ad, a somber documentary, and an angry character line, all without changing your own tone during the recording. This positions it as the ideal tool for dynamic content creators who need their voice to be versatile.
5. The Step-by-Step Guide to Cloning Your Voice
Cloning your voice on a modern platform is a fast and intuitive process. The following steps are based on the Kukarella workflow, which is optimized for both speed and user control.
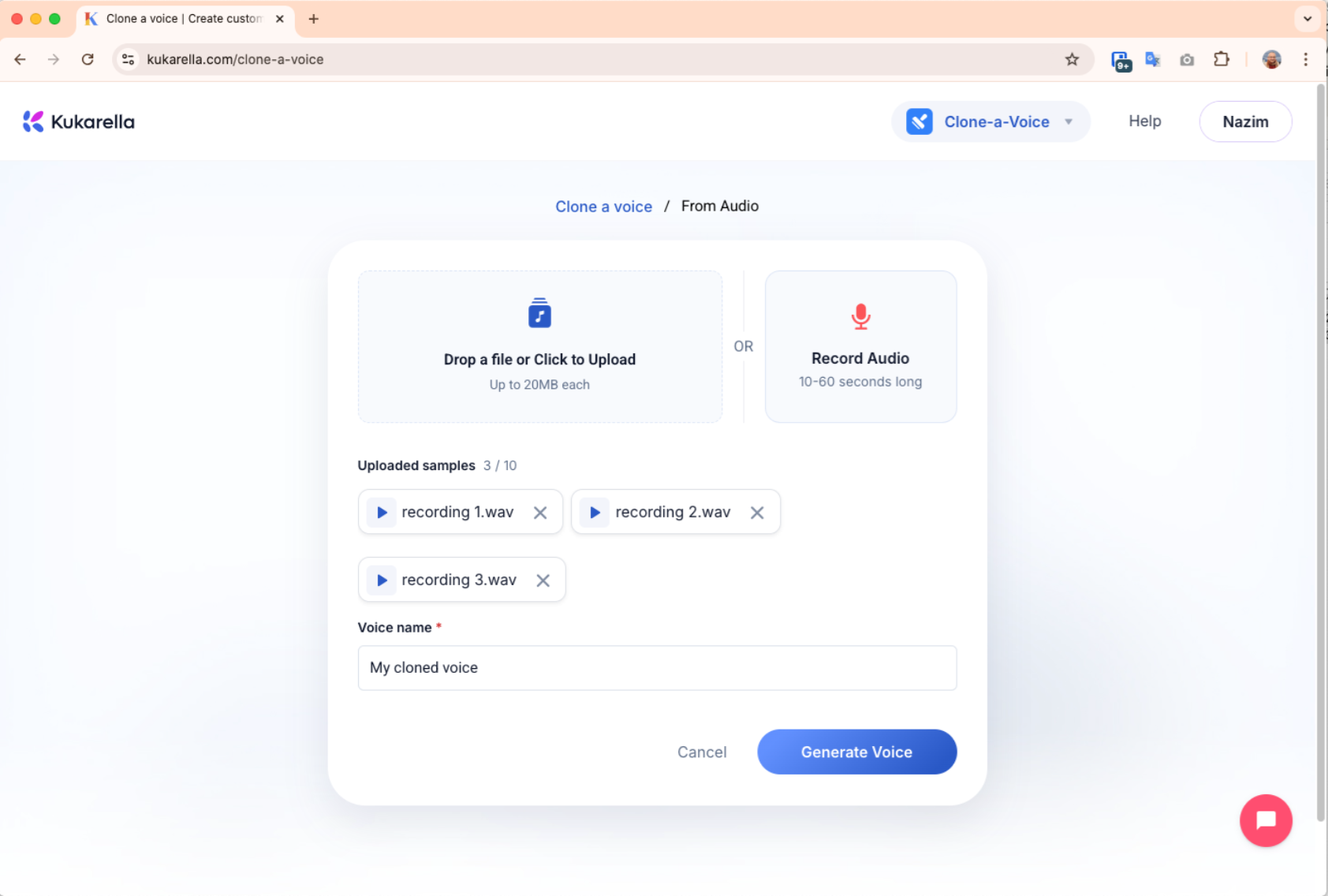
- Step 1: Record or Upload Your 15-Second Voice Sample
- Action: Navigate to the "Clone a Voice" section. You have two options: record your voice directly using the built-in recorder or upload a pre-recorded audio file (MP3 or WAV).
- Pro-Tip (This is the most important part): The quality of this 15-second sample determines everything.

Record in a quiet room, free from echo and background noise. Speak clearly and naturally, as if you were talking to a friend. A flat, monotone recording will result in a flat, monotone clone.
- Step 2: Name Your Voice
- Action: Give your clone a unique, memorable name (e.g., "John_Narrator_Voice").
- Step 3: Generate and Review
- Action: Click the "Generate" button. Within about a minute, the AI will process your sample and create the clone.
- Step 5: Use and Direct Your Voice Clone
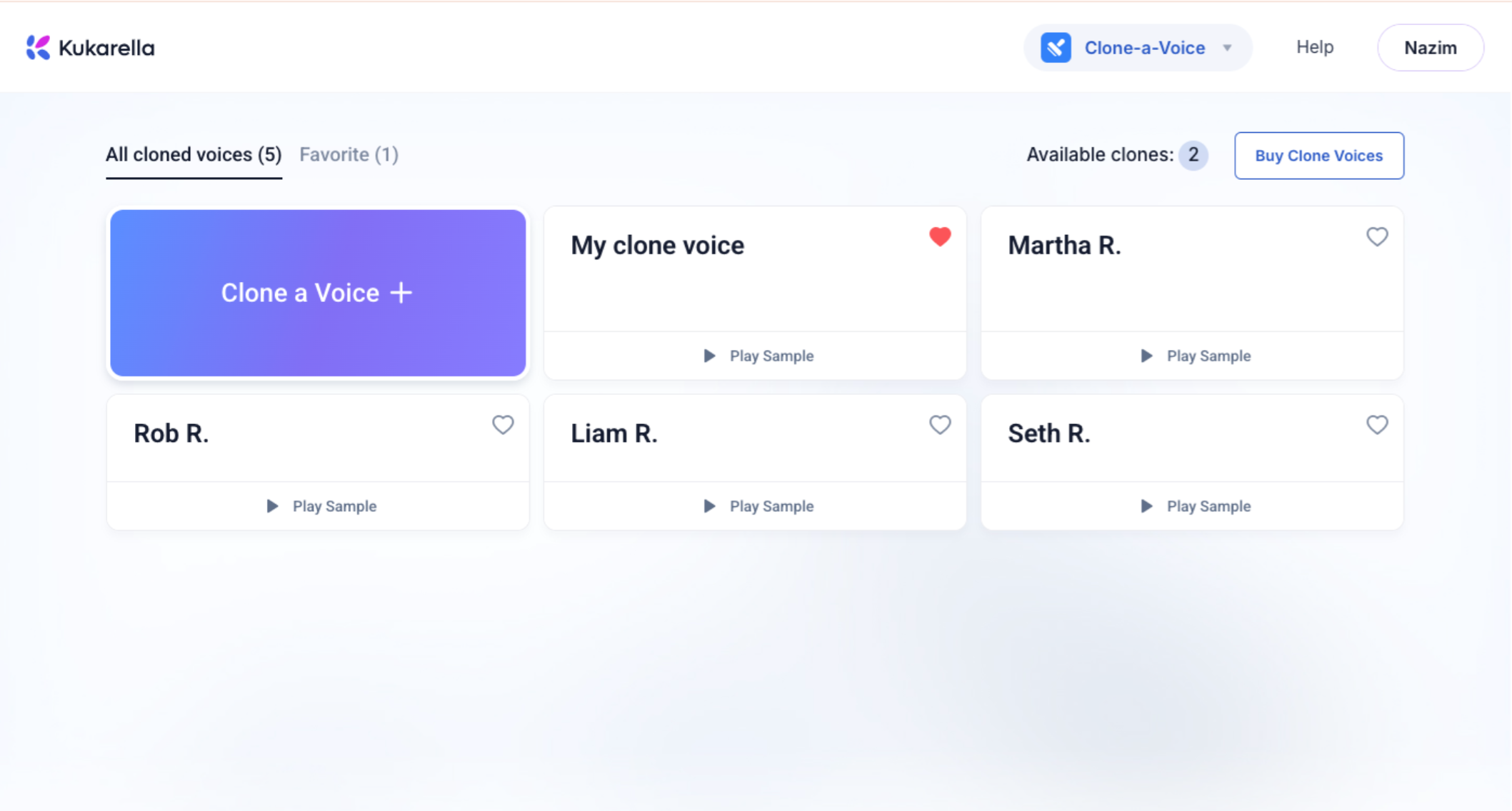
- Action: Your new cloned voice is now available in your voice library. You can use it in two main ways:
- Text to Voice: For straightforward narration, scripts, and audio lessons.
- Dialogues AI App: To have conversations between your cloned voice and other stock AI voices, perfect for creating interviews or educational scenarios.
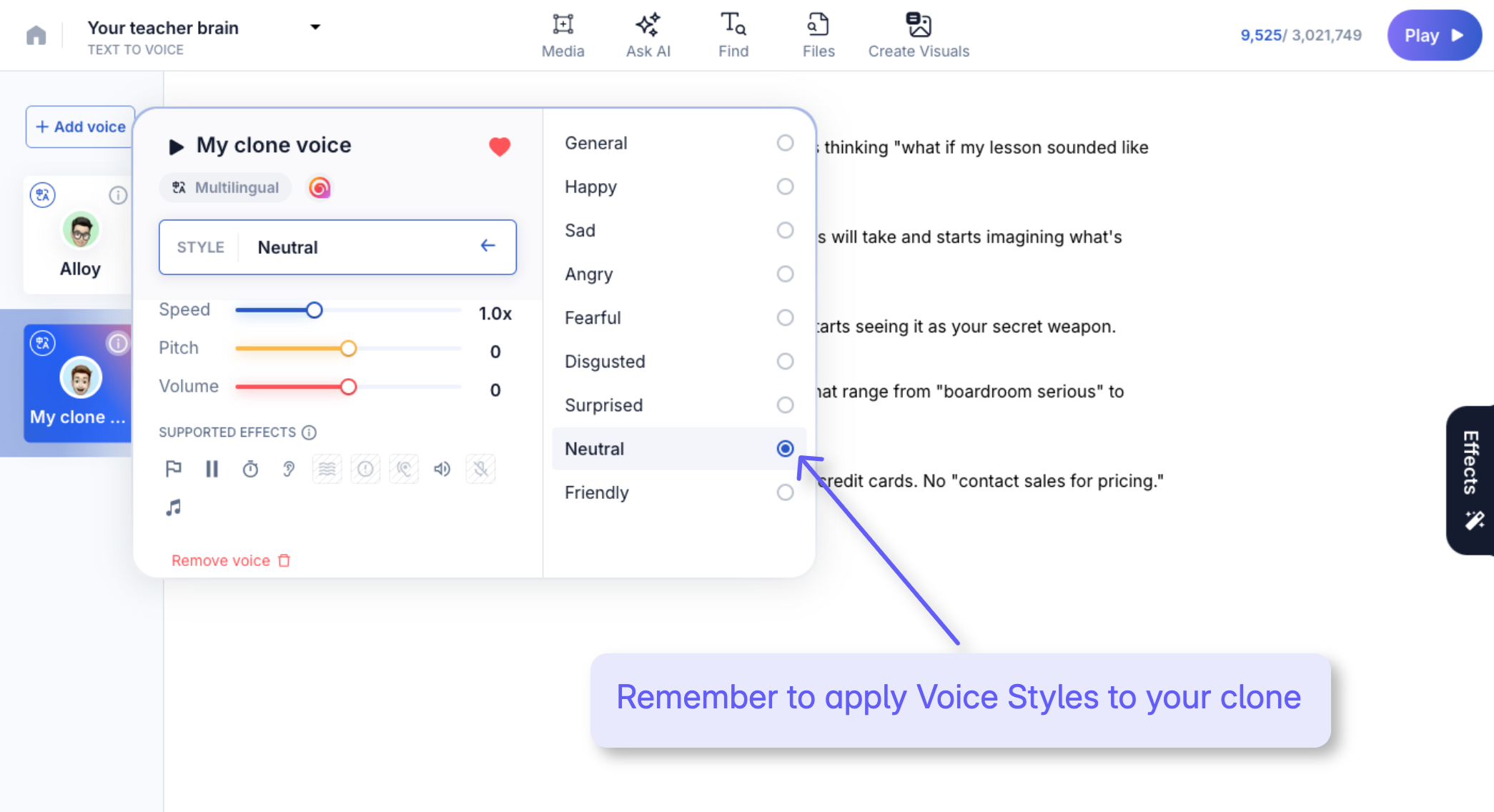
- The Power Step: Remember to apply Voice Styles to your clone to add emotion and change the delivery for different projects, as discussed in the previous section. You can also control Speed, Pitch and Volume of the voice.
- Action: Your new cloned voice is now available in your voice library. You can use it in two main ways:
6. Troubleshooting & Edge Cases
- Problem: "My cloned voice sounds slightly robotic or has a metallic echo."
- Solution: This is almost always due to a poor-quality input sample. Re-record your 15-second clip in a quieter room, move further from reflective surfaces like walls, and use a better microphone if possible.
- Problem: "The clone doesn't capture my accent correctly."
- Solution: The 15-second sample may not have contained enough phonetic diversity. Record a new sample that includes a wider range of sounds and vowel shapes characteristic of your accent.
- Problem: "The emotional styles sound weird on my voice."
- Solution: Your original recording may have been too monotone. The AI needs a baseline with some natural inflection to work from. Record your sample as if you were speaking to a friend, not as if you were reading a list.
7. The Future: Hyper-Personalization and Ethical Guardrails
The future of voice cloning is moving in two opposite but parallel directions:
- Real-Time Expressiveness: Expect models that can change emotion and tone mid-sentence based on contextual cues in the text. You won't just apply a "sad" style to a whole paragraph; the AI will know to make a specific word sound sad.
- Watermarking and Detection: To combat misuse, a huge area of research is "audio watermarking." This involves embedding an imperceptible digital signature into any cloned audio file, making it possible to trace its origin and verify if it's AI-generated. This will be crucial for fighting disinformation and fraud.
8. Your Action Plan & Ethical Checklist
Ready to create your own voice double?
- Step 1: Define Your Purpose. Why are you cloning your voice? For fixing podcast errors? For creating consistent tutorials? Your goal will determine which tool is best.
- Step 2: Prepare Your Recording Space. Find the quietest room you can. Turn off fans, close windows, and put your phone on silent.
- Step 3: Choose Your Platform. For speed and emotional versatility, a platform like Kukarella is an excellent starting point. For maximum realism, you might explore a pro plan on ElevenLabs.
- Step 4: Follow the Cloning Tutorial. Record, upload, and generate your first audio clip.
- Step 5: The Ethical Check. Before you publish anything, ask yourself these questions:
- Is this my own voice, or do I have explicit permission to use it?
- Could this audio be used to deceive or mislead someone?
- Should I disclose that this is an AI-generated voice? (For public content, the answer is almost always yes).
9. The Fine Print: An Essential Warning on Voice Cloning Ethics and Data Privacy

While the technology is incredible, the ethics and privacy policies behind voice cloning platforms vary dramatically. Not all voice cloning services are created equal, and choosing the wrong one can expose you to significant risks.
The "Perpetual License" Problem
In early 2025, a major shift happened in the AI voice space. Some platforms, like ElevenLabs, updated their Terms of Service to include a clause granting them a "perpetual, irrevocable, royalty-free, worldwide license" to use the voice recordings and models uploaded by their users.
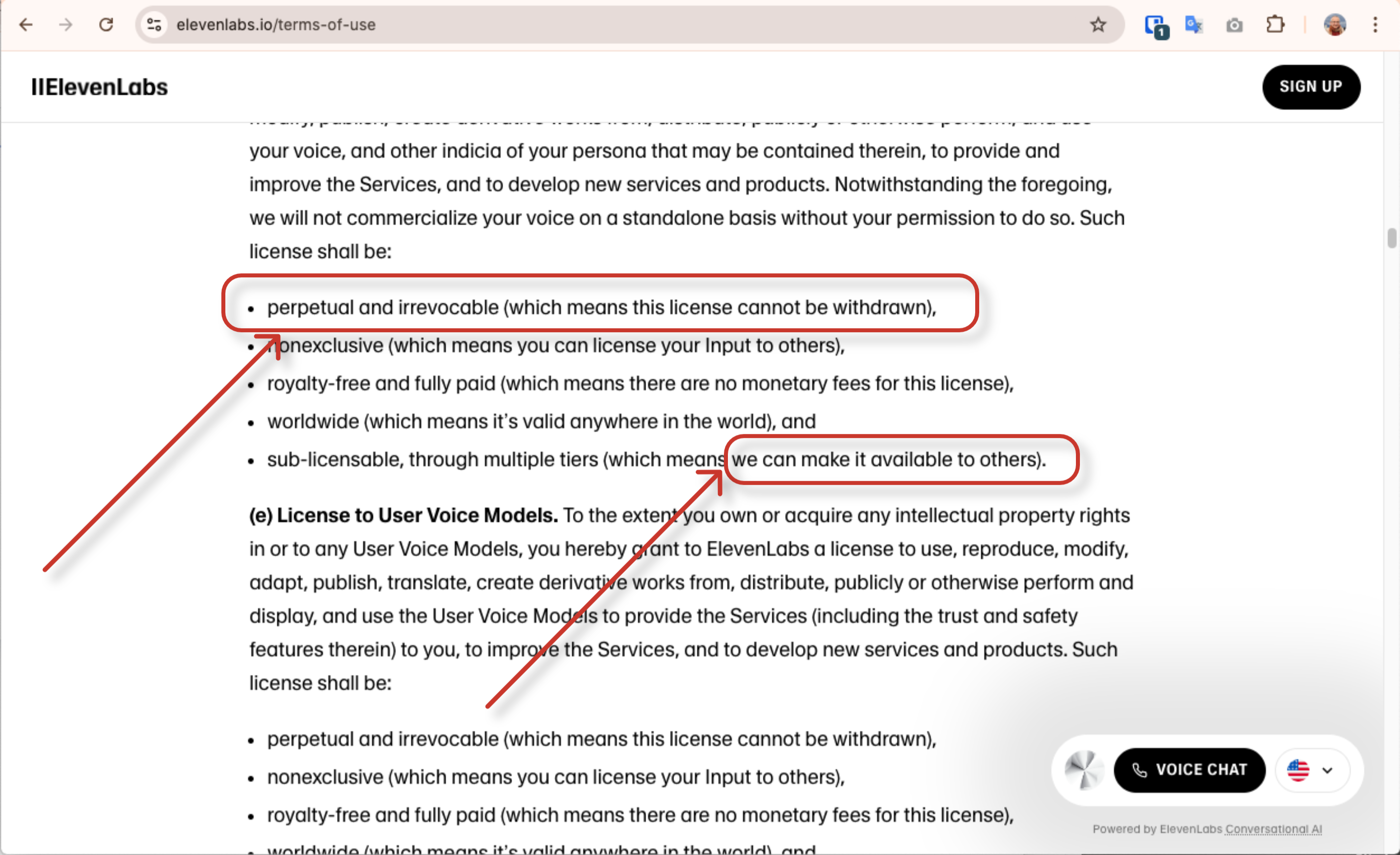
- What This Means: Even if you delete your account, the company could potentially retain the right to use the unique biometric data of your voice indefinitely. This creates unnerving scenarios. Your voice model could be used to train other AI systems, shared with partners, or become part of a massive corporate data ecosystem—all without your ongoing consent.
Your Voice Is Your Biometric Identity
These concerns aren't theoretical. A voiceprint is as unique as a fingerprint. When your voice data is shared, especially with massive entities like Google Cloud (as part of the ElevenLabs partnership), the risk of misuse increases. Scenarios include:
- Your voice pattern being used to train fraud detection algorithms without your permission.
- Scammers using publicly available voice models to create deepfake calls to family members.
The Privacy-First Alternative
In response to these changes, platforms like Kukarella have deliberately positioned themselves as privacy-first providers. This approach is built on a different philosophy:
- Full Ownership: You retain full ownership and control of your voice data.
- Clear Deletion: When you request data deletion, it is permanently removed from the systems.
- No Perpetual License: The platform does not claim perpetual rights to your biometric voice data or the models created from it.
Reality Check: Read the Terms of Service
Before you upload your voice to any platform, read their terms on data ownership and licensing. Are you granting them a perpetual license? Do you retain full ownership? Answering these questions is the most important step you can take to protect your digital identity.
This makes the choice of a voice cloning platform not just a technical decision about quality, but a critical security decision about who you trust with your unique vocal identity. The rest of this guide, including the sections on the future and the action plan, remains highly relevant.